相似度检测——hnsw参数选择


最近在做一个相似度检测的项目,虽然目前技术很成熟,项目也比较简单,但是算法应用过程的一些参数如何选择,刚开始的时候还是一头雾水,毕竟现在做什么算法都要优化,所以记录一下选参过程。
Part 1. 论文中讨论到的参数
Part 2. 实际项目中的应用
参考论文:
简单列一下相似度搜索过程:分层查找+独立集合的graph neighbor选择


原理参考: https://blog.csdn.net/u011233351/article/details/85116719 通透!!
Part 1. 论文中讨论到的参数
在使用这个算法的时候涉及到了以下几个参数的选择,这些参数都会对精度、构造时间、搜索时间、RAM大小有不同的影响:
- 什么特征作为输入
- 特征维度 d
- M
- efConstruction
- dataset大小对搜索时间的影响
- 测量方法
接下来我将一个个罗列出来分析。
一. 什么特征作为输入,以图像分析为例。
1. 原始特征,图像本身作为输入,显然这种情况不说效果如何,最起码数据量上就会很大,对RAM要求极大。一般不会作为输入特征
2. SIFT特征, 图像处理中有很多特征提取方法,其中SIFT有代表性。当然也可以选择其他。这样大大的降低数据量的同时,也能起到降维的作用。将有效特征作为相似度比较的依据比较合理。
3. DEEP特征,目前神经网络比较流行,可以利用这个方法提取特征。
4. 其他特征
特征选择有一个原则:归一化的降维的主要特征。去除冗余点,这对我们后续的相似度检测有着很大的好处。
对于不同特征的数据集,作者也给出了统计信息:




不同的数据特征传入H-NSW算法时,对性能的影响很大。
1. random d=4和MNIST数据特征本身很小,因此性能提升快
2. SIFT和DEEP特征,复杂输入经过这两种处理后可以有效提升性能和响应时间,这两个特征通过图Fig.13对比可以看出DEEP特征较好(开始的QT较小,BF较小)。
二. 特征维度的选择
特征维度的大小与RAM占用,搜索时间,性能快速达到稳定范围关系很大。维度越小,响应速度越快,性能提升越快。对于简单的问题,可以选择小维度,复杂问题适当选择大的维度。相同数量级的数据集,维度越大,RAM占用越大,搜索时间越长。
作者也给出的统计:


三. M和efConstruction
M是这么解释的:- the number of bi-directional links created for every new element during construction.
M的合理范围在[2,200]。M越高,对于本身具有高维特征的数据集来讲,recall可能越高,性能越好;M越低,对于本身具有低维特征的数据集来讲,性能越好。
建议M:12,16,32。因为特征已经选择过了,维度一般不会太高。
efConstruction :- the parameter has the same meaning as ef, but controls the index_time/index_accuracy.
ef - the size of the dynamic list for the nearest neighbors (used during the search).
efConstruction 越大,构造时间越长,index quality越好。有时,efConstruction 增加的过快并不能提升index quality。有一种方法可以检查efConstruction 的选择是否可以接受。计算recall,当ef=efConstruction ,在M值时,如果recall低于0.9,那么可以适当增加efConstruction 的数值。
这里还有一个参数max_elements,检索的最大元素。这个参数取决于你创建的索引库的特征数量。如果你想要在1000,0000个特征中检测是否有相似的图像时,这个max_elements就要设置为1000,0000. 当然这也要看RAM是否支持这么多数据同时加载进来。
作者给出了统计信息:

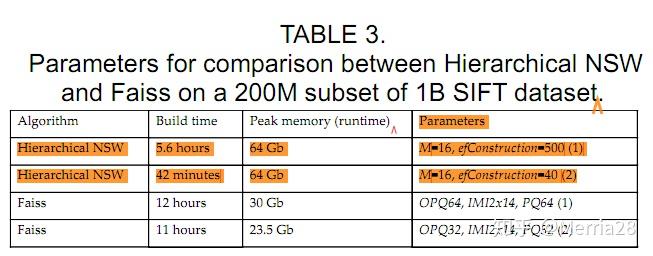


- 对比Faiss,H-NSW需要更大的RAM,但是精度提升很多,并且搜索时间快了很多,参考Fig.15
- efConstruction这个参数越大build time(构造时间)越长;Query time相同时,recall有些许提升;也就是说仅仅改变这个参数对性能提升贡献很小。
四 . dataset大小对搜索时间的影响
从Fig.15中的内置小图可以看到,随着数据量的提升,搜索时间会急剧增大;建议一次搜索的数据量控制在10M以内。如果数据量真的特别大(比如每年的数据量在20M,随着时间的增长,数据量急剧增加),可以分段创建几个索引库,同时搜索,取距离值最小的作为最终的结果。
五. 测量方法
不同的测量方法,得到不同的距离值(相似度检测最后得到两张图像的相似程度[0,1])。当不相似的两张图计算相似度时,需要尽可能的拉大它们之间的距离,利于判断。
下面罗列一下作者提到的几个方法,具体哪个好,需要根据数据集测试效果。
Distance parameter Equation
Squared L2 'l2' d = sum((Ai-Bi)^2)
Inner product 'ip' d = 1.0 - sum(Ai*Bi))
Cosine similarity 'cosine' d = 1.0 - sum(Ai*Bi) / sqrt(sum(Ai*Ai) * sum(Bi*Bi))
Part 2. 实际项目中的应用
1. 特征选择
通过Fig.13中的比对,最终选择了DEEP特征作为hnsw算法的输入。
- 对比SIFT特征,DEEP特征可在nueral network中单独提取优化,当训练好之后可快速提取特征。
- BF time是很快的。
- 最终维度可控。我提取的特征是1280*1的一个一维特征。
在提取特征的时候参考的是IBM的Accelerate Reverse Image Search with GPU for feature extraction: https://github.com/IBM/reverse-image-search-gpu-studio 这部分内容稍后会做详细分析。
2. 特征降维
在项目的实际运行过程中,加入了pca降维。主要原因是数据集很大,搜索时间过长,加上精度不理想(不相似的图像与相似的图像区分不开,参考下图第一列数据)。将特征从1280降到了128。
期间尝试过降到256的维度:这样每张图像的特征在1164的大小(hnsw中根据维度计算出的数据大小),那么我半年的数据量是4W*183张图,这样RAM=1164*40000*183,约10G。事实上我需要对比的索引库在3年以内的数据量(想想好可怕)。
实验对比如下:
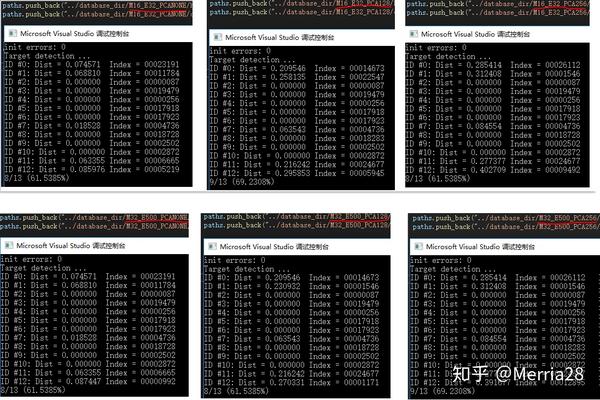

上图中dist>0的数据是索引库中没有的图像(有四张测试图),维度d=256时,距离值可以拉的比较开一些,容易区分;对比没有PCA降维的结果,维度d=128时,也是比较好的。
3. 测量方法
根据官网上的提示"ip"方法是这么解释的:Note that inner product is not an actual metric. An element can be closer to some other element than to itself. 也就是说实际中不用考虑这种方法(元素A与A计算出来的结果可能比元素A与B计算出来的结果大,距离越小越相似)。
所以一直采用了“l2”方法计算。后来发现“cosine”方法在扩大不相似的范围上有更好的效果。也就是说,元素A与B不相似,这个值用cosine计算出来更接近1,而l2计算的结果偏小。
4.RAM问题
RAM的问题要看CPU配置了,在算法参数中需要确保max_number*size_per_data小于等于RAM的80%,这样实际中运行比较顺畅。
5. dataset很大的问题
当dataset很大时,会造成两个问题:
- 电脑配置低,无法运行
- 搜索时间过长
这种情况可以适当分段建立几个索引库,这样就能解决。当然了你想要的加快搜索速度,比如多线程搜索几个索引库,必须提高电脑配置。这样既能保证精度,也能提升速度。